

How can I work with file based data in a Big Data Cluster?
So far, we’ve deployed a Big Data Cluster and explored its Data Virtualization capabilities.
Now with this article (formally published on PASS Community Blog) it’s time to look how you can use your Big Data Cluster to consume file-based data from for example a CSV or Parquet file. The Big Data Cluster component to be used for that is the so-called Storage Pool.
Is there anything I should know before getting started?
You will need to have access to a Big Data Cluster – like the one we’ve deployed in the first post – as well as Azure Data Studio.
Also, you will need some file-based data. Our example will be using the 2015 flight delay dataset, which you get for free at https://www.kaggle.com/usdot/flight-delays.
You will also need your BDC’s gateway endpoint to access HDFS files.
To retrieve that, you have 2 options:
Open a command prompt and run
azdata login
azdata will prompt you for your namespace (if you deployed using the default: sqlbigdata), username and password. You can then run the following command:
azdata bdc endpoint list -o table
which will return the endpoints again. This time look for the “Gateway to access HDFS files, Spark”:

The other option would be to go through Azure Data Studio. Connect to your Big Data Cluster, right-click the Server and choose “Manage”:

If you switch to the “SQL Server Big Data Cluster” pane on the next screen, you will see all the endpoints of your instance:

How can I get data into the storage pool?
Getting data into your storage pool can again be achieved through Azure Data Studio as well as through the command line. The latter is the preferred way when you’re automating the upload of your data – for example hourly logfiles from your webserver.
Let’s first take a look at how to do that in Azure Data Studio. If you connect to a Big Data Cluster, ADS will show a node for your HDFS. If you right click it, you can create new directories and upload files:

Create a directory “FlightDelays” and upload the files “flights.csv” and “airlines.csv”. If you expand the HDFS node and your newly created directory, both files should show up:
Another way of uploading files would be through curl using this command:
curl -s -S -L -k -u root:<Password> -X PUT "https://<endpoint>/gateway/default/webhdfs/v1/<target>?op=create&overwrite=true" -H "Content-Type: application/octet-stream" -T "<sourcefile>"
In our case, this would look like this (replace your endpoint accordingly):
curl -s -S -L -k -u root:MySQLBigData2019 -X PUT "https://13.88.129.102:30443/gateway/default/webhdfs/v1/FlightDelays/airports.csv?op=create&overwrite=true" -H "Content-Type: application/octet-stream" -T "airports.csv"
If you refresh your folder in ADS, the third file should show up as well:
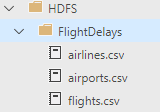
How can I make that data usable?
Now that we’ve uploaded some data to the storage pool, we need to make it accessible for SQL Server. To do this, we need an external data source within our database, a file format and an external table point to either a file or to a directory. If you point your external table to a directory, all files in the directory will be used and will need to have the same structure.
Azure Data Studio also provides a Wizard for flat files. Right click the file “airlines.csv” in in ADS and click “Create External Table From CSV Files”:

This will open up another 4-step wizard. In the first step, you will define which database to create the external table in as well as its name and schema. You will also define the name of the external data source (leave this as SqlStoragePool) as well as the name for the file format (change this to CSV):

The next step will just give you a preview of your data whereas the third step is important, as this is where you will define your column names and data types:

As most other tools and wizards for flat files, it will try to guess the data types for each column but will only use a limited sample size. Also, it is rather pessimistic for some data types (while none of the entries for IATA_CODE contains more or less than 2 characters or any Unicode characters, it recommends NVARCHAR(50) as the data type) and potentially too optimistic for others. If you were not provided a proper schema for your file(s), this may end up in a trial and error approach.
The last step will provide you an overview of what you’ve configured in the wizard, again with the option to immediately create those objects or script them.
Choose “Generate Script” and look at the output. The first part of the script creates the external data source, pointing to the storage pool:
USE [DataVirt]; CREATE EXTERNAL DATA SOURCE [SqlStoragePool] WITH (LOCATION = N'sqlhdfs://controller-svc/default');
The next step creates a (rather generic) file format:
CREATE EXTERNAL FILE FORMAT [CSV] WITH (FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR = N',', STRING_DELIMITER = N'\"', FIRST_ROW = 2));
The last step creates the external table which will use the previously created format and data source:
CREATE EXTERNAL TABLE [dbo].[airlines] ( [IATA_CODE] nvarchar(50) NOT NULL, [AIRLINE] nvarchar(50) NOT NULL ) WITH (LOCATION = N'/FlightDelays/airlines.csv', DATA_SOURCE = [SqlStoragePool], FILE_FORMAT = [CSV]); For the other two files, you can either go through the wizard again or just create them by running these two statements:
CREATE EXTERNAL TABLE [dbo].[airports] ( [IATA_CODE] nvarchar(50) NOT NULL, [AIRPORT] nvarchar(100) NOT NULL, [CITY] nvarchar(50) NOT NULL, [STATE] nvarchar(50) NOT NULL, [COUNTRY] nvarchar(50) NOT NULL, [LATITUDE] float, [LONGITUDE] float ) WITH (LOCATION = N'/FlightDelays/airports.csv', DATA_SOURCE = [SqlStoragePool], FILE_FORMAT = [CSV]); CREATE EXTERNAL TABLE [dbo].[flights] ( [YEAR] bigint NOT NULL, [MONTH] bigint NOT NULL, [DAY] bigint NOT NULL, [DAY_OF_WEEK] bigint NOT NULL, [AIRLINE] nvarchar(50) NOT NULL, [FLIGHT_NUMBER] bigint NOT NULL, [TAIL_NUMBER] nvarchar(50), [ORIGIN_AIRPORT] nvarchar(50) NOT NULL, [DESTINATION_AIRPORT] nvarchar(50) NOT NULL, [SCHEDULED_DEPARTURE] time NOT NULL, [DEPARTURE_TIME] time, [DEPARTURE_DELAY] bigint, [TAXI_OUT] bigint, [WHEELS_OFF] time, [SCHEDULED_TIME] bigint NOT NULL, [ELAPSED_TIME] bigint, [AIR_TIME] bigint, [DISTANCE] bigint NOT NULL, [WHEELS_ON] time, [TAXI_IN] bigint, [SCHEDULED_ARRIVAL] time NOT NULL, [ARRIVAL_TIME] time, [ARRIVAL_DELAY] bigint, [DIVERTED] bit NOT NULL, [CANCELLED] bit NOT NULL, [CANCELLATION_REASON] nvarchar(50), [AIR_SYSTEM_DELAY] bigint, [SECURITY_DELAY] bigint, [AIRLINE_DELAY] bigint, [LATE_AIRCRAFT_DELAY] bigint, [WEATHER_DELAY] bigint ) WITH (LOCATION = N'/FlightDelays/flights.csv', DATA_SOURCE = [SqlStoragePool], FILE_FORMAT = [CSV]);
You will notice that the latter two tables make use of the same data source and connection. If you expand your database and its tables in ADS, you will also see the three tables:
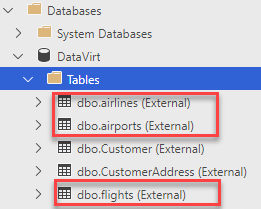
How can I query that data?
Just like with data from external data sources as described in our previous post, this data can be queried as if it were coming from a local table:
SELECT * FROM airlines SELECT * FROM airports
And of course, you can also join those tables against each other or against other tables in your database:
SELECT TOP 10 fl.AIRLINE,al.*, fl.FLIGHT_NUMBER FROM flights fl INNER JOIN airlines al on fl.AIRLINE = AL.IATA_CODE
If the structure of your file doesn’t match your external table definition – for example if you’ve defined a column and a SMALLINT that contains larger numbers, you would see a data conversion error including the information which column and row caused the issue. In this case, you would need to recreate your external table using the proper data types.
That seems slow…
While performance may not be bad for smaller files like airlines.csv, queries tend to get very slow once they get even slightly bigger. Therefore, I highly recommend converting those files into the parquet format first. This can also be done from within your Big Data Cluster.
The Microsoft samples on GitHub contain an example on how to convert a CSV into a parquet file as well as on how to add an external table based on a parquet file.
What if I have additional questions?
Please feel free to reach out to me on Twitter: @bweissman – my DMs are open. Also make sure to check out the posts by my friend Mohammad Darab – he has a ton of content prepared for you!