

What is Data Virtualization in Big Data Clusters?
This article (formally published on PASS Community Blog) is part two of our mini series. In the previous post, we’ve deployed a Big Data Cluster. Now it’s time to use this system and get some work done on it.
Let’s start with a feature called “Data Virtualization” which is basically PolyBase 2.0. While PolyBase (unlike other BDC features) is also available for standalone SQL Server 2019 installations, it plays an essential role in the BDC architecture. It allows you to bring in data from other data sources like SQL Server, Oracle, Teradata. It also allows you to bring in data from SharePoint, CRM or Cloudera through the concept of an external table.
Is there anything I should know before getting started?
You will need to have access to a Big Data Cluster – like the one we’ve deployed in the previous post – as well as Azure Data Studio.
In Azure Data Studio, you will need the “Data Virtualization” extension which can be found in the marketplace. Navigate to the extensions, search for “Data Virtualization” and click “Install” on the extension as shown in this picture:

Also, create a database called “DataVirt”, which we will be using for this exercise.
How can you add data from other sources?
Microsoft provides a wizard for external data coming from SQL Server and Oracle through the extension that we’ve just installed.
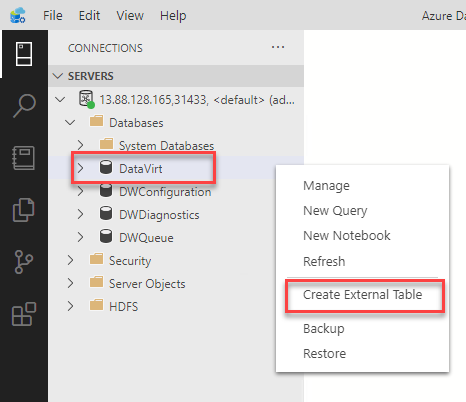
Let’s try to bring in some data from another SQL Database sitting in Azure. To start the wizard, connect to your Big Data Cluster, right click on the DataVirt data and click “Create External Table”:
The wizard will first ask you for a data source, which will be SQL Server.
In the next step, you will be asked for a database master key which is required as we will be storing credentials in the database to access the external data source.
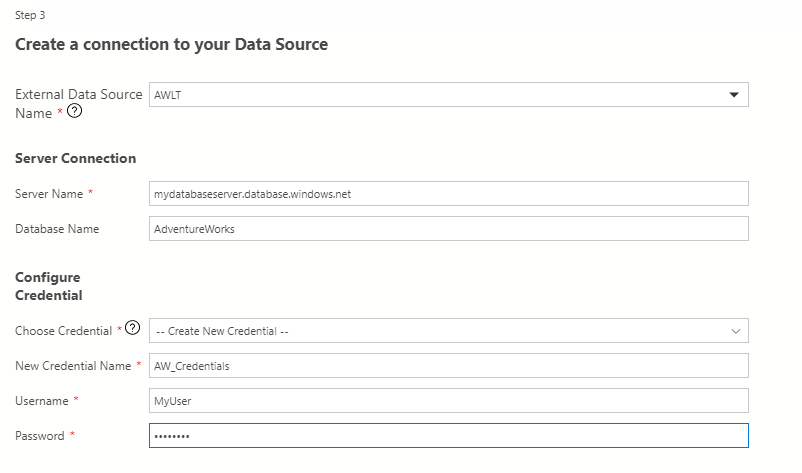
Now we will provide the connection details for our data source which will consist of a connection (connection-, server- and database name) as well as the credentials (credential- and username and password):
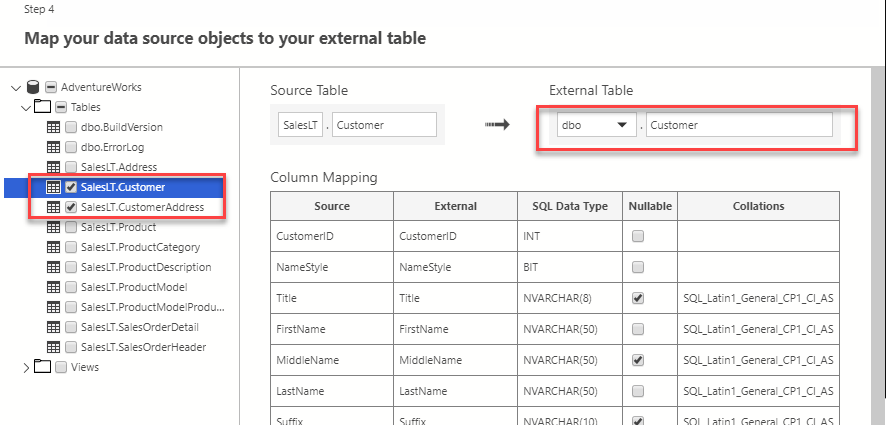
The wizard will now connect to this database and read the metadata from it. You can either tick the whole database or just a few tables. You will not be able to change data types or select/unselect specific columns as the structure of the external table will need to match your underlying source. Of course, you can still only select specific columns or cast datatypes in your queries. What you can change though is the tables name and schema where it will be created in:
After choosing the tables that you need (for this exercise, it doesn’t matter which ones you pick), you will be given a summary and the option to either just run create the objects you’ve just defined or create a script out of it:

If you pick “Create script”, you’ll basically see that there are four different commands, all enclosed by a transaction. The first step creates your master key.
This is followed by the credentials to be used for the connection:
CREATE DATABASE SCOPED CREDENTIAL [AW_Credentials] WITH IDENTITY = N'<myUser>', SECRET = N'<myPassword>';
Next, we will define the data source which is a link to a database server in combination with the previously created credential:
CREATE EXTERNAL DATA SOURCE [AWLT] WITH (LOCATION = N'sqlserver://bwaw.database.windows.net', CREDENTIAL = [AW_Credentials]);
Based on this data source, we can now define one or multiple external tables. You will notice, that the code looks very similar to a regular CREATE TABLE script with the exception, that it’s not pointing to a file group but an external data source:
CREATE EXTERNAL TABLE [dbo].[CustomerAddress] ( [CustomerID] INT NOT NULL, [AddressID] INT NOT NULL, [AddressType] NVARCHAR(50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, [rowguid] UNIQUEIDENTIFIER NOT NULL, [ModifiedDate] DATETIME2(3) NOT NULL ) WITH (LOCATION = N'[AdventureWorks].[SalesLT].[CustomerAddress]', DATA_SOURCE = [AWLT]);
If you run these scripts, you will have created all required objects to query data from your external source within your local database.
To bring in external data from sources other than SQL Server or Oracle, you will need to come up with the T-SQL yourself as laid out in the documentation.
How can I query this data?
That’s the beauty! If you created an external table called dbo.Customer, you can query it as if it were a local table:
SELECT * FROM Customer
Unlike when using a linked server, you won’t need to include server names or anything similar.
From a user perspective, this process is completely transparent, unless you look at the execution plan:
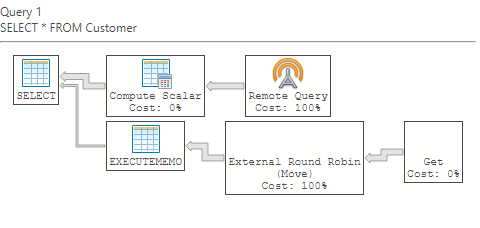
Anything that happens outside of your local environment will show as a “Remote Query”.
Are there any caveats?
Of course! Keep in mind, while it may be great to be able to access those external tables in real-time, it might also cause huge problems. Latency between SQL Server and the external data source comes to mind. You may be consuming data for analytical workloads which would require different caching and indexing techniques than a direct query to your OLTP source. Also, you may want to track certain changes in a slowly changing dimension so while data virtualization may be a great enhancement for some of your use cases, it’s not going to make your ETL needs go away.
What if I have additional questions?
Please feel free to reach out to me on Twitter: @bweissman – my DMs are open. Also, there is one more post coming up, showing you how to use file-based data sources in the BDC storage pool.